Con la popolarità dei LLM (Large Language Model), i database vettoriali sono diventati un argomento popolare. Con soltanto poche righe di semplice codice Python, un database vettoriale può fungere da “cervello esterno” economico ma altamente efficace per il tuo LLM. Ma abbiamo davvero bisogno di un database vettoriale specializzato?
Perché i LLM ha bisogno di una ricerca vettoriale?
Introduciamo innanzitutto il motivo per cui i LLM devono fare uso della tecnologia di ricerca vettoriale. La ricerca vettoriale è un problema che esiste da molto tempo e consiste nel trovare l’oggetto più simile in una raccolta dato un oggetto di riferimento. Testi, immagini e altri tipi di dati possono essere convertiti in una rappresentazione vettoriale, trasformando così il problema della somiglianza tra testi/immagini in un problema di somiglianza vettoriale.
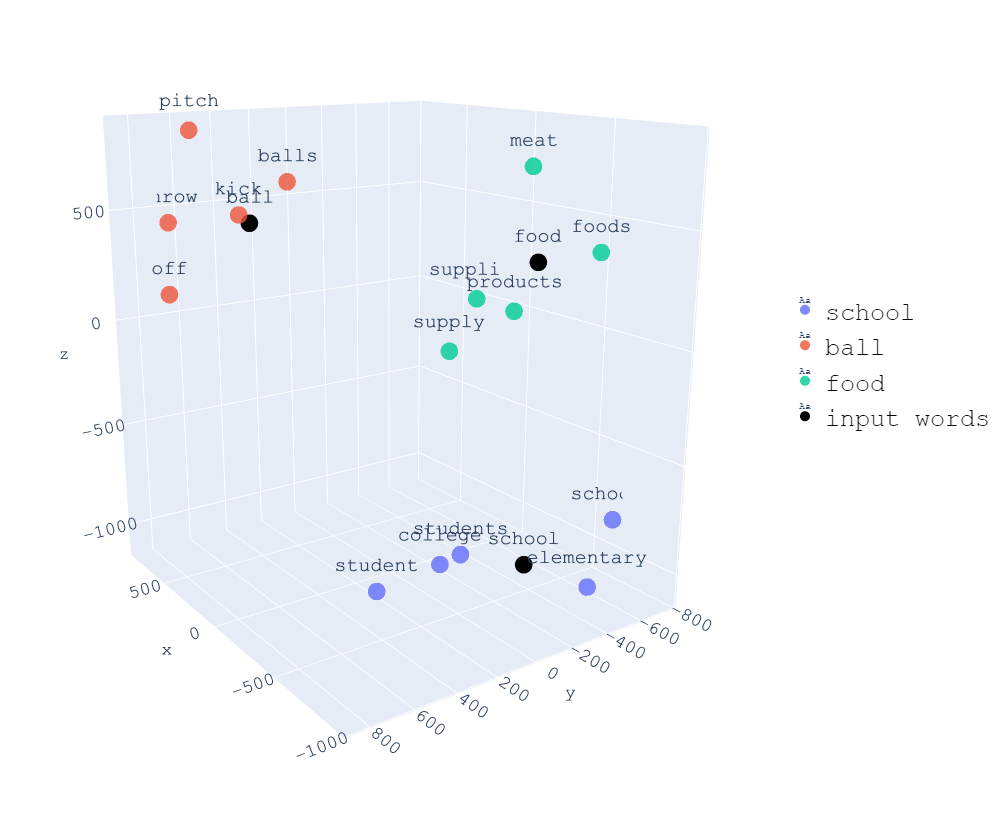
Nell’esempio sopra, convertiamo parole diverse in un vettore tridimensionale, permettendoci di visualizzare intuitivamente la somiglianza tra diverse parole in uno spazio 3D. Ad esempio, la somiglianza tra “studente” e “scuola” è maggiore della somiglianza tra “studente” e “cibo”.
Tornando ai LLM, la limitazione della lunghezza della finestra di contesto rappresenta una sfida importante. Ad esempio, ChatGPT 3.5 ha un limite di lunghezza del contesto di 4k token. Questo costituisce un problema significativo per la capacità dei LLM di apprendere il contesto e ha un impatto negativo sull’esperienza utente del modello. Tuttavia, la ricerca vettoriale fornisce una soluzione a questo problema:
- Dividi il testo che supera il limite di lunghezza del contesto in blocchi più brevi e converti blocchi diversi in vettori (embedding);
- Prima di immettere il prompt in LLM, convertirlo in un vettore (embedding);
- Cerca il vettore del prompt per trovare il vettore del blocco più simile.
- Concatenare il vettore di blocco più simile con il vettore del prompt come input in LLM.
È come fornire ai LLM una memoria esterna che consente loro di cercare le informazioni più rilevanti in questa memoria. Questa abilità è resa possibile dalla ricerca vettoriale.
Perché il database vettoriale è così popolare?
Nei LLM, il database vettoriale è diventato una parte indispensabile, e uno dei motivi è la sua facilità d’uso. Utilizzando modelli come OpenAI Embedding (come text-embedding-ada-002), è possibile convertire una query prompt in un vettore e eseguire l’intero processo di ricerca vettoriale con soli circa dieci righe di codice.
def query(query, collection_name, top_k=20):
# Creates embedding vector from user query
embedded_query = openai.Embedding.create(
input=query,
model=EMBEDDING_MODEL,
)["data"][0]['embedding']
near_vector = {"vector": embedded_query}
# Queries input schema with vectorized user query
query_result = (
client.query
.get(collection_name)
.with_near_vector(near_vector)
.with_limit(top_k)
.do()
)
return query_resultNel contesto dei LLM, la ricerca vettoriale riveste principalmente un ruolo nel recupero delle informazioni. In breve, il recupero implica trovare gli oggetti più simili all’interno di un insieme di candidati. Nei LLM, l’insieme dei candidati è costituito da tutti i blocchi di testo, e l’oggetto più simile è il blocco che meglio corrisponde al prompt. Nel processo di ragionamento dei LLM, la ricerca vettoriale viene considerata come l’implementazione principale del recupero. È facile da implementare e può fare uso dei modelli di embedding di OpenAI per risolvere il problema della conversione del testo in vettori. La parte rimanente del processo è un problema di ricerca vettoriale indipendente e pulito, che può essere efficacemente gestito dagli attuali database vettoriali. Pertanto, l’intero processo procede in modo particolarmente fluido.
Come suggerisce il nome, un database vettoriale è progettato specificamente per gestire dati rappresentati come vettori. In passato, il calcolo della somiglianza tra vettori richiedeva un tempo computazionale elevato, con una complessità di O(n^2), poiché richiedeva il confronto di ogni vettore nell’insieme con tutti gli altri. Per affrontare questo problema, l’industria ha introdotto l’algoritmo di Nearest Neighbor Approssimato (ANN). Con l’uso di ANN, viene costruito un indice vettoriale precalcolato nel database, sfruttando il concetto di scambio di spazio con tempo. Questo processo accelera notevolmente il calcolo della somiglianza tra vettori, in modo simile a come avviene con gli indici nei database tradizionali.
Pertanto, i database vettoriali non solo hanno ottime prestazioni ma anche un’eccellente facilità d’uso, rendendoli perfetti per LLM! (Veramente?)
Forse sarebbe meglio un database generico?
Abbiamo parlato dei vantaggi e dei benefici dei database vettoriali, ma quali sono i loro limiti? Un post sul blog di SingleStore fornisce una buona risposta a questa domanda:
I vettori e la ricerca vettoriale rappresentano un tipo di dati e un approccio all’elaborazione delle query, non la base per un nuovo modo di elaborare i dati. L’utilizzo di un database vettoriale specializzato (SVDB) porterà ai soliti problemi che vediamo (e risolviamo) ancora e ancora con i nostri clienti che utilizzano più sistemi specializzati: dati ridondanti, spostamento eccessivo di dati, mancanza di accordo sui valori dei dati tra i componenti distribuiti, extra costo del lavoro per competenze specializzate, costi di licenza aggiuntivi, potenza limitata del linguaggio di query, programmabilità ed estensibilità, integrazione limitata degli strumenti e scarsa integrità e disponibilità dei dati rispetto a un vero DBMS.
Ci sono due questioni importanti. La prima è il problema della coerenza dei dati. Durante la fase di prototipazione, i database vettoriali sono molto adatti e la facilità d’uso è più importante di ogni altra cosa. Tuttavia, un database vettoriale è un sistema indipendente che è completamente disaccoppiato da altri sistemi di archiviazione dati come i database TP e i data lake AP. Pertanto, i dati devono essere sincronizzati, trasmessi in streaming ed elaborati tra più sistemi.
Immagina se i tuoi dati fossero già archiviati in un database OLTP come PostgreSQL. Per eseguire la ricerca vettoriale utilizzando un database vettoriale indipendente, è necessario prima estrarre i dati dal database, quindi convertire ciascun punto dati in un vettore utilizzando servizi come OpenAI Embedding e quindi sincronizzarli con un database vettoriale dedicato. Ciò aggiunge molta complessità. Inoltre, se un utente elimina un punto dati in PostgreSQL ma questa eliminazione non viene riflessa nel database vettoriale, si verificheranno problemi di incoerenza dei dati. Questo problema può essere molto serio negli ambienti di produzione reali.
-- Update the embedding column for the documents table
UPDATE documents SET embedding = openai_embedding(content) WHERE length(embedding) = 0;
-- Create an index on the embedding column
CREATE INDEX ON documents USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
-- Query the similar embeddings
SELECT * FROM documents ORDER BY embedding <-> openai_embedding('hello world') LIMIT 5;D’altra parte, se tutto viene eseguito in un database generico, l’esperienza dell’utente potrebbe essere più semplice rispetto a quella con un database vettoriale indipendente. I vettori sono solo un tipo di dati in un database generico, non costituiscono un sistema indipendente. In questo modo, la coerenza dei dati non è più un problema.
Il secondo problema riguarda il linguaggio di query. Il linguaggio di query dei database vettoriali è generalmente progettato specificamente per la ricerca vettoriale, quindi potrebbero esserci molte limitazioni in altri tipi di query. Ad esempio, negli scenari di filtraggio dei metadati, gli utenti devono filtrare in base a determinati campi di metadati. Gli operatori di filtro supportati da alcuni database vettoriali sono limitati.
Inoltre, anche i tipi di dati supportati per i metadati sono molto limitati e in genere includono solo String, Number, List of Strings e Booleans. Questo non è amichevole per query di metadati complesse.
Se i database tradizionali possono supportare il tipo di dati vettoriale, i problemi sopra menzionati non esistono. In primo luogo, la coerenza dei dati è già garantita poiché i database TP o AP sono infrastrutture esistenti negli ambienti di produzione. In secondo luogo, il problema del linguaggio di query non esiste più perché il tipo di dati vettoriale è solo un tipo di dati nel database, quindi le query per il tipo di dati vettoriale possono utilizzare il linguaggio di query nativo del database, come SQL.
Spiegazione dettagliata
Tuttavia, non è giusto confrontare solo gli svantaggi dei database vettoriali. Ci sono diversi contrappunti da considerare:
- Facilità d’uso : i database vettoriali sono progettati pensando alla facilità d’uso e gli utenti possono lavorare facilmente con essi senza preoccuparsi dei dettagli di implementazione sottostanti. Tuttavia, integrarli con altri sistemi di archiviazione dati può rappresentare una sfida, come accennato in precedenza;
- Prestazioni : i database vettoriali presentano un vantaggio significativo rispetto ai database tradizionali in termini di prestazioni per determinati casi d’uso. Il loro design per la ricerca vettoriale consente ricerche di somiglianza veloci ed efficienti su set di dati su larga scala con vettori ad alta dimensione;
- Filtraggio dei metadati : sebbene le funzionalità di filtraggio dei metadati nei database vettoriali possano essere limitate, possono comunque soddisfare le esigenze della maggior parte degli scenari aziendali. Tuttavia, per query di metadati più complesse, potrebbe essere necessario un approccio ibrido, in cui i metadati vengono archiviati in un database o data Lake separato e collegati ai dati vettoriali nel database vettoriale.
Come affrontare questi problemi? Nella sezione seguente, forniremo una prospettiva rispondendo a queste domande.
I database vettoriali sono facili da usare
Anche se è vero che i database vettoriali sono facili da usare, ciò non riguarda solo loro. La facilità d’uso dei database vettoriali è dovuta principalmente alla loro astrazione di un dominio specifico, che consente loro di essere progettati appositamente per il linguaggio di programmazione di apprendimento automatico più comunemente utilizzato, Python, ed essere ottimizzati per scenari di ricerca vettoriale. Tuttavia, se i database tradizionali potessero supportare anche il tipo di dati vettoriale, potrebbero offrire una facilità d’uso simile.
Inoltre, i database tradizionali possono fornire SDK Python e altri strumenti integrati per soddisfare le esigenze della maggior parte degli scenari, nonché interfacce SQL standard per gestire scenari di query più complessi. Pertanto, non è necessario utilizzare un database vettoriale esclusivamente per la sua facilità d’uso.
Un altro vantaggio dei database vettoriali è il loro design distribuito che consente loro di scalare orizzontalmente per soddisfare i requisiti di volume di dati e QPS degli utenti. Tuttavia, i database tradizionali possono soddisfare questi requisiti anche attraverso sistemi distribuiti. Tuttavia, la decisione di utilizzare un sistema distribuito dovrebbe essere basata sulle effettive esigenze del volume di dati e sui requisiti QPS, nonché sui costi associati.
In sintesi, sebbene i database vettoriali abbiano i loro vantaggi, i database tradizionali possono anche fornire una facilità d’uso e funzionalità distribuite simili se supportano il tipo di dati vettoriale. Pertanto, la scelta tra un database vettoriale e un database tradizionale dovrebbe essere basata sulle esigenze specifiche dell’applicazione e sulle risorse disponibili.
I database vettoriali hanno prestazioni migliori
Per studiare le prestazioni dei database vettoriali negli scenari LLM, è stato condotto un naive benchmark del recupero dei vettori. Il benchmark ha coinvolto N vettori inizializzati casualmente a 256 dimensioni, e il tempo di interrogazione per i primi 5 più vicini è stato misurato per diverse scale di N. Per il test sono stati utilizzati due metodi diversi:
- Numpy è stato utilizzato per eseguire calcoli in tempo reale , che eseguiva un calcolo completamente accurato e non precalcolava i vicini più prossimi;
- Hnswlib è stato utilizzato per precalcolare i vicini più vicini approssimativi.
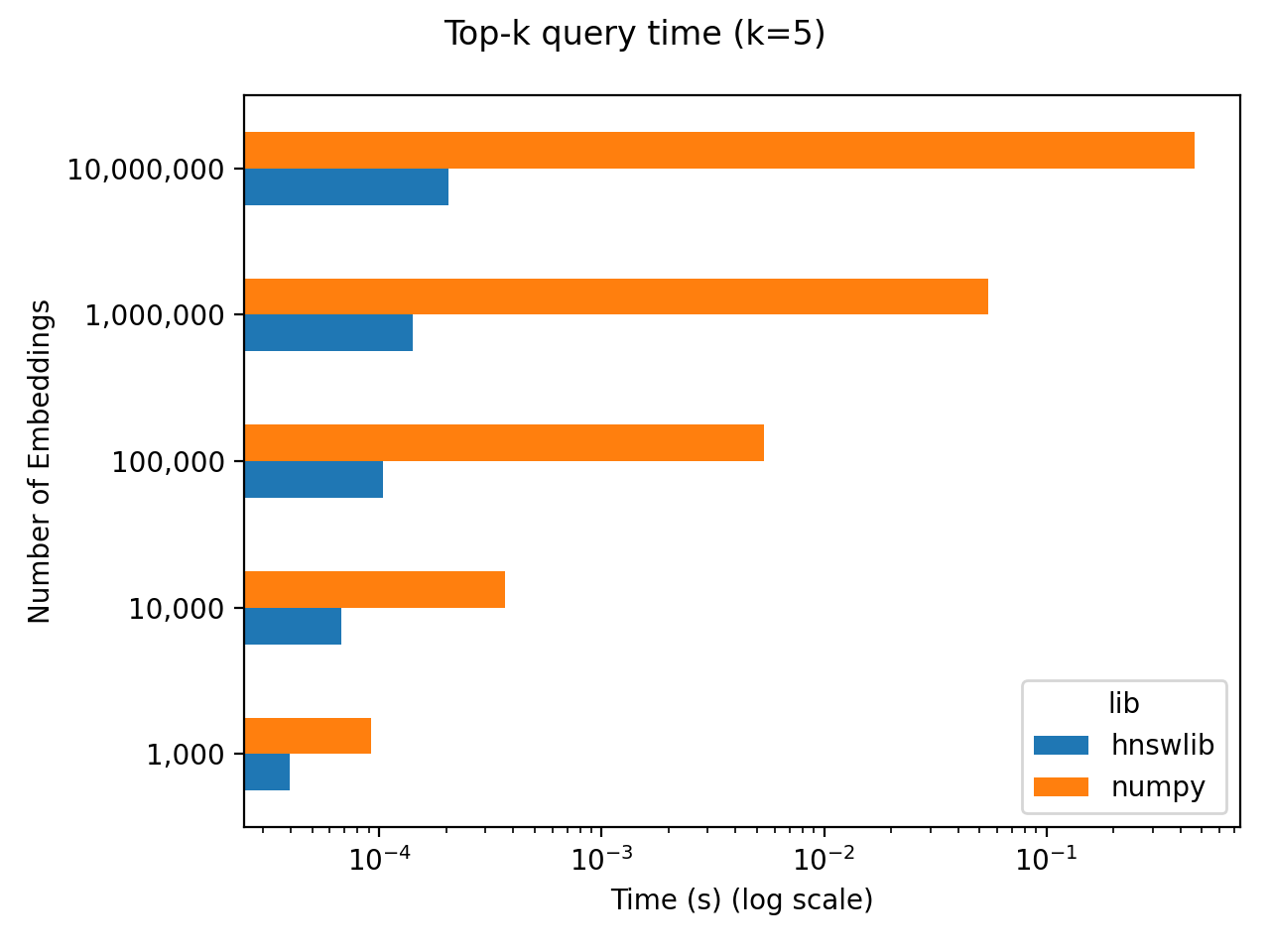
I risultati del benchmark mostrano che, su una scala di un milione di vettori, il ritardo del calcolo in tempo reale utilizzando Numpy è di circa 50 ms. Utilizzando questo come punto di riferimento, possiamo confrontare il tempo impiegato nell’inferenza LLM dopo aver completato la ricerca vettoriale. Ad esempio, il modello 7B richiede circa 10 secondi per l’inferenza su 300 caratteri cinesi su una Nvidia A100 (40GB). Pertanto, anche considerando il tempo di query per il calcolo accurato in tempo reale della somiglianza di un milione di vettori utilizzando Numpy, esso rappresenta solo lo 0,5% del ritardo totale nell’inferenza LLM end-to-end. Pertanto, in termini di ritardo, i benefici apportati dai database vettoriali potrebbero essere oscurati dal ritardo del LLM stesso nell’attuale scenario LLM.
Pertanto, dobbiamo considerare anche il throughput. Il rendimento di LLM è molto inferiore a quello dei database vettoriali. Pertanto, non credo che il throughput sia il problema principale in questo scenario.
Se la prestazione non è la preoccupazione principale, quali fattori determineranno la scelta dell’utente? Potrebbe essere la facilità d’uso complessiva, inclusa la facilità d’uso sia per l’uso che per il funzionamento, la coerenza e altre soluzioni ai problemi relativi al database. I database tradizionali dispongono di soluzioni mature per questi problemi, mentre i database vettoriali sono ancora nelle prime fasi di sviluppo.
Il filtraggio dei metadati può comunque soddisfare le esigenze della maggior parte degli scenari aziendali
Quando si considera il filtraggio dei metadati, è importante notare che non è solo una questione di numero di operatori supportati. Anche la coerenza dei dati è un fattore cruciale. I metadati nei vettori sono essenzialmente dati nei database tradizionali, mentre i vettori stessi sono indici dei dati. Pertanto, è ragionevole considerare l’archiviazione sia dei vettori che dei metadati nei database tradizionali.
I database tradizionali hanno la capacità di supportare tipi di dati vettoriali e forniscono facilità d’uso e funzionalità distribuite simili a quelle dei database vettoriali. Inoltre, i database tradizionali dispongono di soluzioni mature per garantire la coerenza e l’integrità dei dati, come la gestione delle transazioni e il backup e ripristino dei dati.
I vettori nei database tradizionali
Poiché consideriamo i vettori come un nuovo tipo di dati nei database tradizionali, diamo un’occhiata a come supportare i tipi di dati vettoriali nei database tradizionali, utilizzando PostgreSQL come esempio. pgvector è un plug-in open source per PostgreSQL che supporta tipi di dati vettoriali. pgvector utilizza il calcolo esatto per impostazione predefinita, ma supporta anche la creazione di un indice IVFFlat e il precalcolo dei risultati ANN utilizzando l’algoritmo IVFFlat, sacrificando la precisione del calcolo a favore delle prestazioni. pgvector ha svolto un ottimo lavoro nel supportare i vettori ed è utilizzato da prodotti come Supabase.
Tuttavia, l’algoritmo dell’indice supportato è limitato, poiché supporta solo l’algoritmo IVFFlat più semplice e non è implementata alcuna quantizzazione o ottimizzazione dell’archiviazione. Inoltre, l’algoritmo dell’indice di pgvector non è compatibile con i dischi ed è progettato per l’uso in memoria. Pertanto, gli algoritmi dell’indice vettoriale progettati per il disco, come DiskANN, sono preziosi anche nell’ecosistema dei database tradizionali.

L’estensione di pgvector può essere complessa a causa della sua implementazione nel linguaggio di programmazione C. Nonostante sia open source da due anni, pgvector ha attualmente solo tre contributori. Sebbene l’implementazione di pgvector non sia particolarmente complessa, potrebbe valere la pena considerare di riscriverla in Rust.
La riscrittura di pgvector in Rust può consentire di organizzare il codice in un modo più moderno ed estensibile. Anche l’ecosistema di Rust è molto ricco, con collegamenti Rust esistenti come faiss-rs.
Di conseguenza, è stato creato pgvecto.rs. pgvecto.rs attualmente supporta operazioni di query vettoriali esatte e tre operatori di calcolo della distanza. È in corso il lavoro per progettare e implementare il supporto dell’indice. Oltre a IVFFlat, speriamo di supportare anche più algoritmi di indicizzazione come DiskANN, SPTAG e ScaNN. Accogliamo con favore contributi e feedback dalla community!
pgvecto.rs offre una base di codice moderna ed estensibile con prestazioni e concorrenza migliorate. La sua progettazione e implementazione consentono un’integrazione perfetta con altre librerie e strumenti di machine learning, rendendolo la scelta ideale per scenari di ricerca di similarità.
Con lo sviluppo continuo, pgvecto.rs mira a diventare uno strumento prezioso per i data scientist e i professionisti dell’apprendimento automatico. Il suo supporto per vari algoritmi di indicizzazione e la sua facilità d’uso lo rendono un candidato promettente per applicazioni di ricerca di similarità su larga scala. Ci auguriamo di continuare lo sviluppo e i contributi della comunità.
-- call the distance function through operators
-- square Euclidean distance
SELECT array[1, 2, 3] <-> array[3, 2, 1];
-- dot product distance
SELECT array[1, 2, 3] <#> array[3, 2, 1];
-- cosine distance
SELECT array[1, 2, 3] <=> array[3, 2, 1];
-- create table
CREATE TABLE items (id bigserial PRIMARY KEY, emb numeric[]);
-- insert values
INSERT INTO items (emb) VALUES (ARRAY[1,2,3]), (ARRAY[4,5,6]);
-- query the similar embeddings
SELECT * FROM items ORDER BY emb <-> ARRAY[3,2,1] LIMIT 5;
-- query the neighbors within a certain distance
SELECT * FROM items WHERE emb <-> ARRAY[3,2,1] < 5;Futuro
Man mano che i Large Language Model (LLM) si spostano gradualmente negli ambienti di produzione, i requisiti infrastrutturali stanno diventando sempre più esigenti. L’emergere dei database vettoriali rappresenta un’importante aggiunta all’infrastruttura. Non crediamo che i database vettoriali sostituiranno quelli tradizionali, ma piuttosto che ciascuno di essi potrà sfruttare i propri punti di forza in scenari diversi. L’emergere dei database vettoriali promuoverà anche l’evoluzione dei database tradizionali per supportare i tipi di dati vettoriali.
Ci auguriamo che pgvecto.rs possa diventare una componente importante dell’ecosistema di Postgres, fornendo un migliore supporto vettoriale per Postgres. La sua implementazione in Rust e il supporto per vari algoritmi di indicizzazione lo rendono un candidato promettente per applicazioni di ricerca di similarità su larga scala. Riteniamo che il suo sviluppo e i contributi della community lo aiuteranno a diventare uno strumento prezioso per i data scientist e i professionisti dell’apprendimento automatico.
Vi aspettiamo al prossimo workshop gratuito per parlarne dal vivo insieme a Andrea Guzzo!
Clicca qui per registrarti!
Non perderti, ogni mese, gli approfondimenti sulle ultime novità in campo digital! Se vuoi sapere di più, visita la sezione “Blog“ sulla nostra pagina!